Advent of Code Benchmarking
For a few years now I’ve been enjoying Eric Wastl’s Advent of Code. For those unaware, each year since 2015 Advent of Code provides a 2-part coding challenge every day from December 1st to December 25th.
In previous years, Myself and Chris have been fairly informally trying to
see who was able to produce the fastest code (Me in PHP, Chris in Python). In the final week of last year to
assist with this, we both made our repos
run in Docker and produce time output for each day.
This allowed us to run each other’s code locally to compare fairly without needing to install the other’s dev environment, and made the testing a bit fairer as it was no longer dependant on who had the faster CPU when running their own solution. For the rest of the year this was fine and we carried on as normal. As we got to the end I remarked it would be fun to have a web interface that automatically dealt with it and showed us the scores, but there was obviously no point in doing that once the year was over. Maybe in a future year…
Fast forward to this year. Myself and Chris (and ChrisN) coded up our Day 1 solutions as normal and then some other friends started doing it for the first time. I remembered my plans from the previous year and suggested everyone should also docker-ify their repos… and so they agreed…
Now, I’m not one who is lacking in side-projects, but with everyone making their code able to run with a reasonably-similar docker interface, and the first couple of days not yet fully scratching the coding-itch, I set about writing what I now call AoCBench.
The idea was simple:
- Check out (or update) code
- Build docker container
- Run each day multiple times and store time output
- Show fastest time for each person/day in a table.
And the initial version did exactly that. So I fired up an LXC container on one of my servers and set it off to start running benchmarks and things were good.

Pretty quickly the first problem became obvious - it was running everything every time which as I added more people really slowed things down, so the next stage was to make it only run when code changed.
In the initial version, the fastest time from 10 runs was the time that was used for the benchmark. But some solutions had wildly-varying times and sometimes “got lucky” with a fast run which unfairly skewed the results. We tried using mean times. Then we tried running the benchmarks more often to see if this resulted in more-alike times. I even tried making it ignore the top-5 slowest times and then taking the mean of the rest. These still didn’t really result in a fair result as there was still a lot of variance. Eventually we all agreed that the median time was probably the fairest given the variance in some of the solutions.
But this irked me somewhat, there was no obvious reason some of the solutions should be so variant.
It seemed like it was mostly the PHP solutions that had the variance, even after switching my container to alpine (which did result in quite a speed improvement over the non-alpine one) I was still seeing variance.
I was beginning to wonder if the host node was too busy. It didn’t look too busy, but it seemed like the
only explanation. Moving the benchmarking container to a different host node (that was otherwise empty) seemed
to confirm this somewhat. After doing that (and moving it back) I looked some more at the host node. I found an
errant fail2ban process sitting using 200% CPU, and killing this did make some improvement (Though
the node has 24 cores, so this shouldn’t really have mattered too much. If it wasn’t for AoCBench I wouldn’t
even have noticed that!). But the variance remained, so I just let it be. Somewhat irked, but oh well.
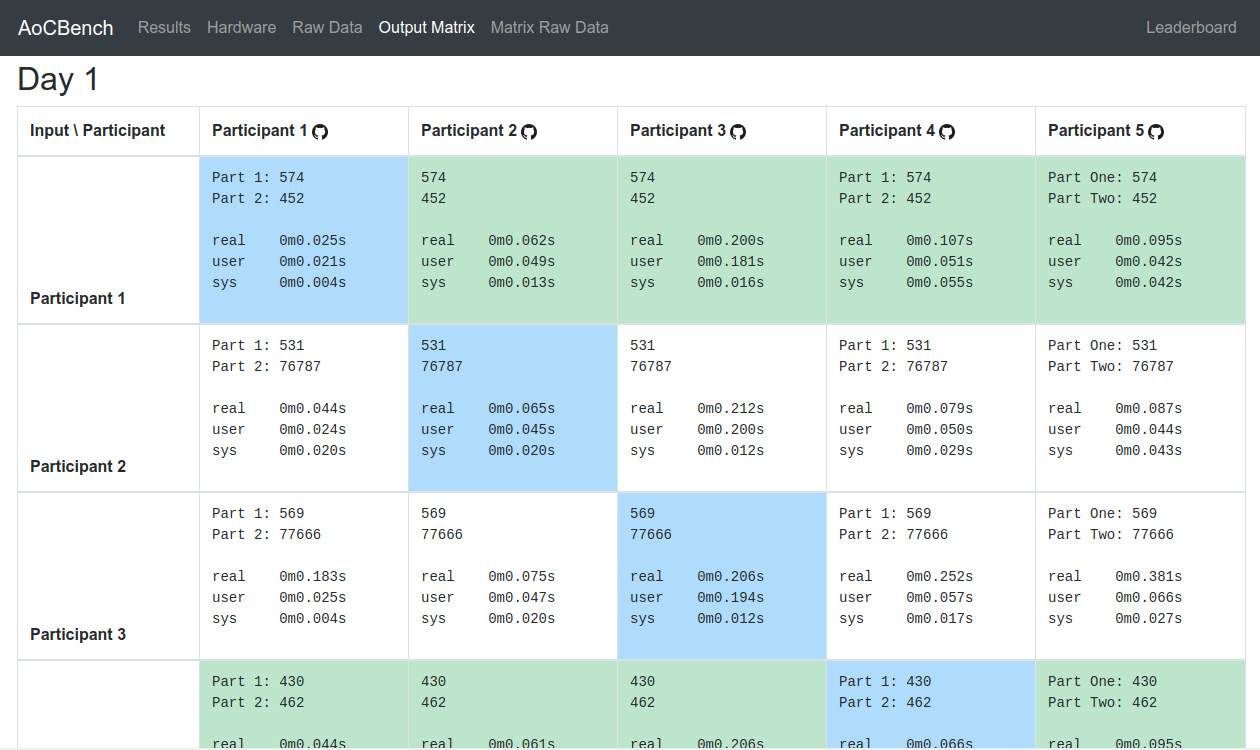
We spent the next few evenings all optimising our solutions some more, vying for the fastest code. To level the playing feed some more, I even started feeding everyone the same input to counter the fact that some inputs were just fundamentally quicker than others. After ensuring that everyone was using the same output, the next step was to ensure that everyone gave the right answer and removing them from the table if they didn’t (This caught out a few “optimisations” that optimised away the right answer by mistake!). I also added support for running each solution against everyone else’s input files and displaying this in a grid to ensure that everyone was working for all inputs not just their own (or the normalised input that was being fed to them all).
After all this, the variance problem was still nagging away. One day in particular resulted in huge variances in some solutions (from less than 1s up to more than 15s some times). Something wasn’t right.
I’d already ruled out CPU usage from being at fault because the CPU just wasn’t being taxed. I’d added a
sleep-delay between each run of the code in case the host node scheduler was penalising us for using a lot of
CPU in quick succession. I’d even tried running all the containers from a tmpfs RAM disk in case
the delay was being caused reading in the input data, but nothing seemed to help.
With my own solution, I was able to reproduce the variance on my own local machine, so it wasn’t just the chosen host node at fault. But why did it work so much better with no variance on the idle host node? And what made the code for this day so much worse than the surrounding days?
I began to wonder if it was memory related. Neither the host node or my local machine was particularly
starved for memory, but I’d ruled out CPU and DISK I/O at this stage. I changed my code for Day 3 to use
SplFixedArray and pre-allocated the whole array at start up before then interacting with it. And
suddenly the variance was all but gone. The new solution was slow-as-heck comparatively, but there was no more
variance!
So now that I knew what the problem was (Presumably the memory on the busy host node and my local machine is quite fragmented) I wondered how to fix it. Pre-allocating memory in code wasn’t an option with PHP so I couldn’t do that, and I also couldn’t pre-reserve a block of memory within each Docker container before running the solutions. But I could change the benchmarking container from running as an LXC Container to a full KVM VM. That would give me a reserved block of memory that wasn’t being fragmented by the host node and the other containers. Would this solve the problem?
Yes. It did. The extreme-variance went away entirely, without needing any changes to any code. I re-ran all the benchmarks for every person on every day and the levels of variance were within acceptable range for each one.
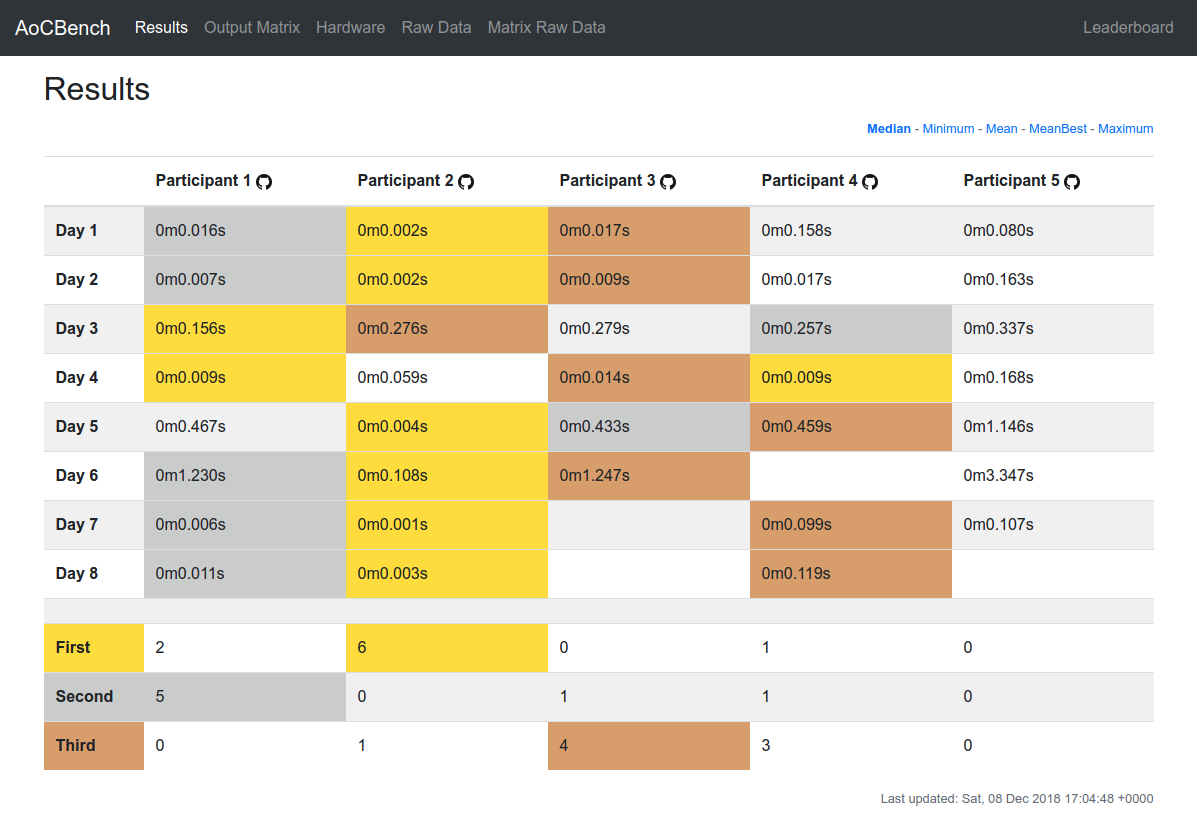
The next major change came about after Chris got annoyed by python (even under pypy) being unable to compete with the speed improvements that PHP7 has made, and switched to using Nim. Suddenly most of the competition was gone. The compiled code wins every time. every. time. (Obviously). So Podium Mode was added to allow for competing for the top 3 spaces on each day.
Finally, after a lot of confusion around implementations for Day 7 and how some inputs behaved differently than others in different ways in different code, the input matrix code was extended to allow feeding custom inputs to solutions to weed out miss-assumptions and see how they respond to input that isn’t quite so carefully crafted.
If anyone wants to follow along, I have AoCBench running here - and I have also documented here the requirements for making a repo AoCBench compatible. The code for AoCBench is fully open source under the MIT License and available on GitHub
Happy Advent of Code all!